Apr 29, 2018 tags: | exploratory analysis |
Analysis of submissions to /r/dataisbeautiful
Browsing reddit is a popular pastime for many people. Besides being an endless supply of entertainment, reddit is also a source of inspiration — especially /r/dataisbeautiful, a community of visual connoisseurs. Let’s see if we can learn anything by analyzing 4716 submissions made over approximately 4 months.
Data collection
The first part of my dataset was obtained using reddit’s own list of 1,000 latest submissions. The source code for downloading, parsing and analysis is available in my github repository. I also procured additional data using an external reddit indexer which allows filtering by subreddit and date. Unfortunately, the index doesn’t get updated whenever a post is deleted by moderators, hence a significant portion of the submissions was spam. I was able to filter it out in R using the following snippet which looks for non-ASCII characters and performs rudimentary analysis of user post history. Between 10 and 20% of the rejected data points were false positives which resulted in the loss of up to 2% of good data points.
# exclude spam
# detect non-ascii characters in the title, no user flair, low post points, no original content flag
spam <- results[grepl("[^ -~]", results$title)&
results$uflair==0&
results$points<2&
results$ocflag==FALSE, ]
results <- results[!(results$url %in% spam$url),]
suspects <- results %>% group_by(user) %>% # list of suspected spammers
summarize(unique_pts = n_distinct(points), # number of elements in the distribution of post points
num_posts = n(), # number of posts
sum_oc = sum(ocflag)) %>% # sum of original content flags
filter(unique_pts<2, num_posts>1, sum_oc == 0)
spam <- rbind(results[results$user %in% suspects$user,], spam) # filter out spam using the list of suspected spammers
results <- results[!(results$user %in% suspects$user),]
There were 4716 submissions left after spam rejection and further pruning.
Analysis
Every submission attracts up-votes and down-votes whose difference determines the overall points. The majority of posts receive only a few points. New submissions are sometimes briefly included in the “popular” category on /r/dataisbeautiful, and if they fail to attract attention within a short period of time, they get dropped. The more attractive submissions remain in the “popular” category until they are toppled by even more popular posts. In rare cases popular submissions are also included on reddit’s front page where they attract a large number of votes from outside of the r/dataisbeautiful community.


The distribution of approval ratings (up-votes divided by the total number of votes) is left-skewed with the mode around 90%. There are a few prominents peaks (at 50, 60 and 100%) attributed exclusively to posts that received only a few points.


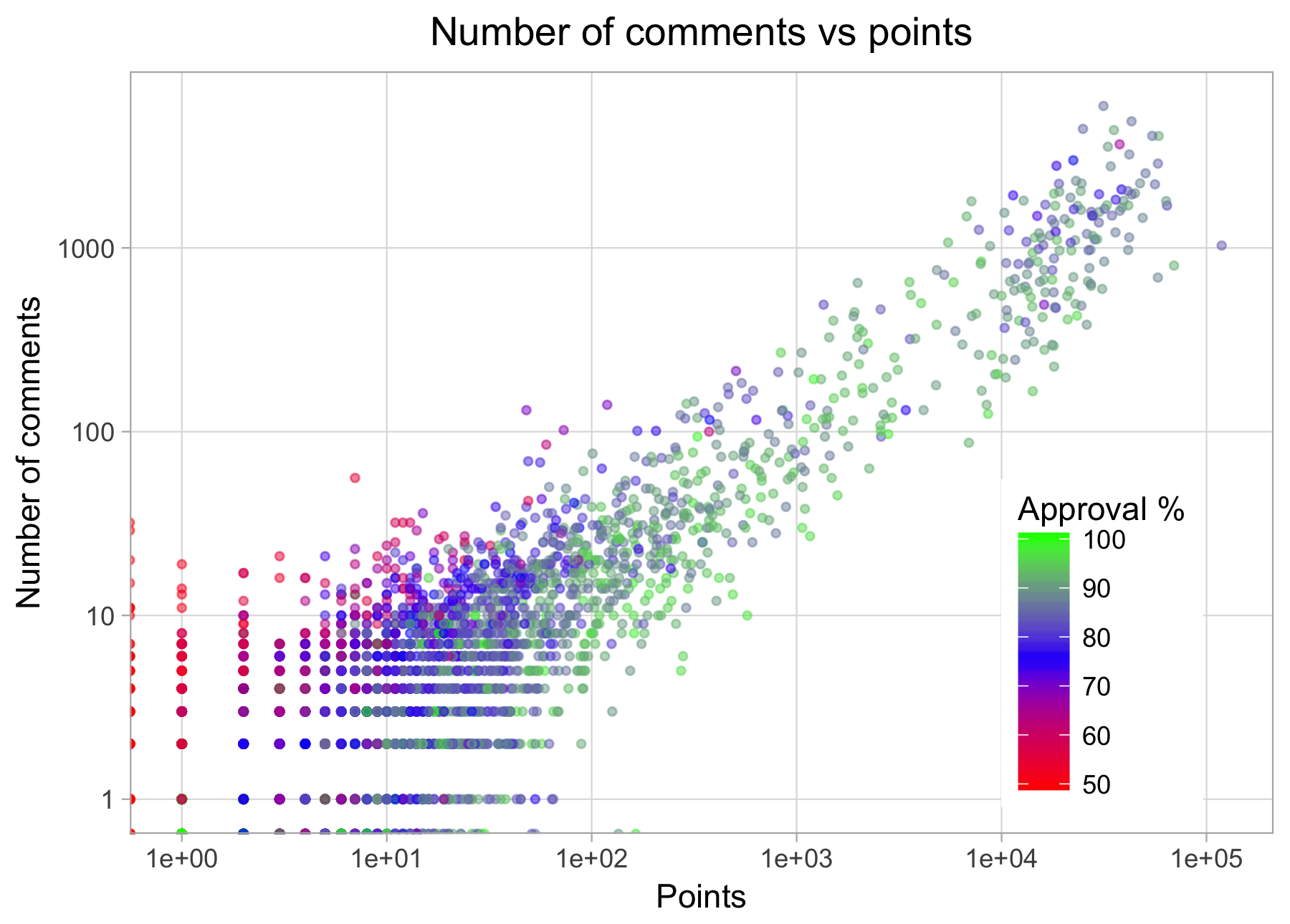
Unsurprisingly, the number of comments a submission attracts scales with the number of points it receives.
Occurrence of top 10% submissions (>136 points) is not even throughout the day/week. Some time slots show three times the normal number of top 10% posts. Whether it is because of increased visibility during these times or merely the schedule of top posters is unclear at the moment.
